Topic
Venue
Show
PDF
 ICPC 2026
ICPC 2026
 ICPC 2026
ICPC 2026
Understanding Codebase like a Professional! Human–AI Collaboration for Code Comprehension
🏆 ACM SIGSOFT Distinguished Paper Award
★ Selected
[Website]
Understanding Codebase like a Professional! Human–AI Collaboration for Code Comprehension
🏆 ACM SIGSOFT Distinguished Paper Award
★ Selected
[Website]
PDF
The 4th HCI+NLP Workshop at EMNLP2025
 The 4th HCI+NLP Workshop at EMNLP2025
The 4th HCI+NLP Workshop at EMNLP2025
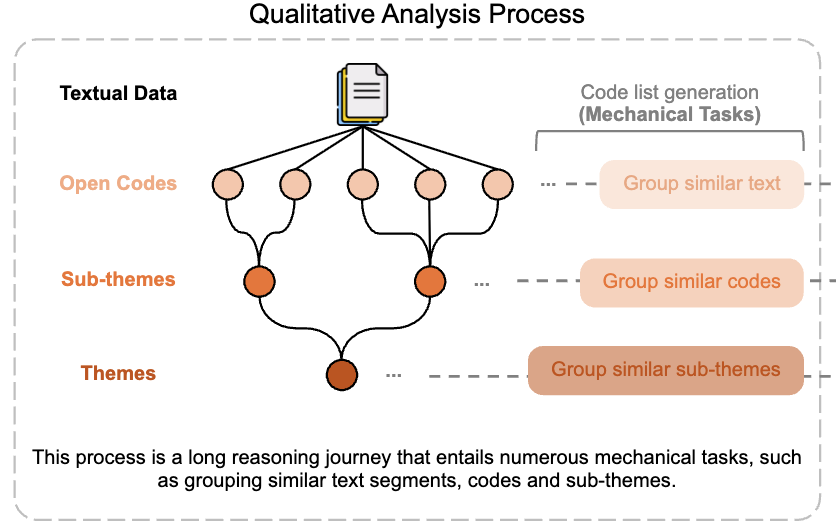
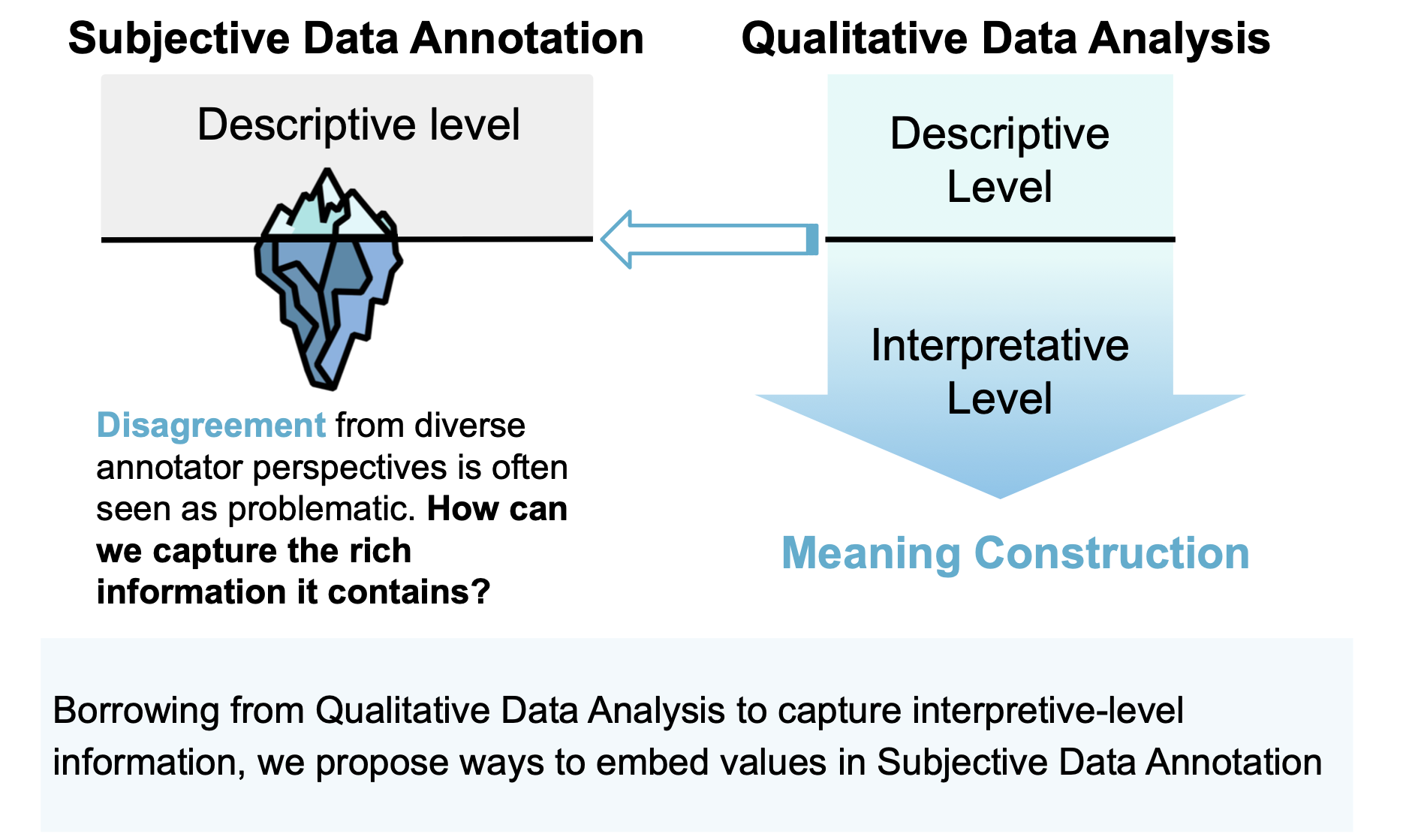
From Noise to Nuance: Enriching Subjective Data Annotation through Qualitative Analysis
# advising author
From Noise to Nuance: Enriching Subjective Data Annotation through Qualitative Analysis
# advising author
PDF
Ph.D. Thesis (2024)
Tool Support for Human-AI Collaboration in Qualitative Data Analysis
★ Selected
Tool Support for Human-AI Collaboration in Qualitative Data Analysis
★ Selected
PDF
CHI 2024
 CHI 2024
CHI 2024
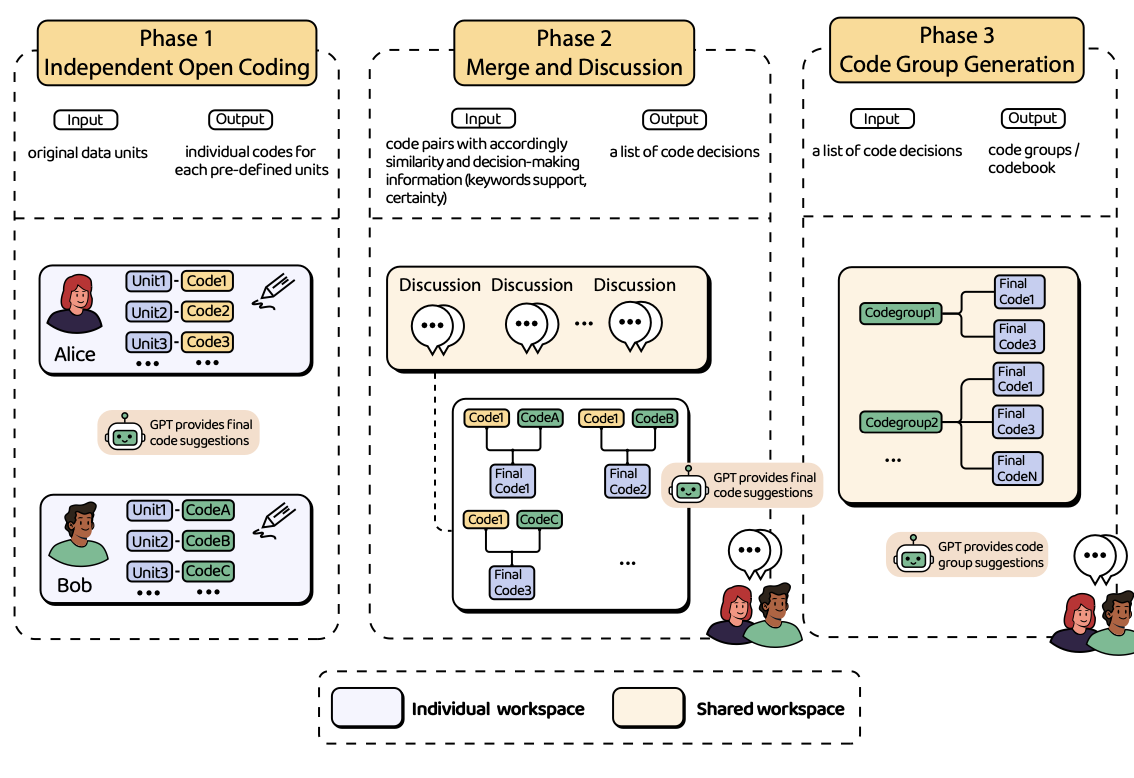
CollabCoder: A Lower-barrier, Rigorous Workflow for Inductive Collaborative Qualitative Analysis with Large Language Models
CollabCoder: A Lower-barrier, Rigorous Workflow for Inductive Collaborative Qualitative Analysis with Large Language Models
PDF
CHI 2024
 CHI 2024
CHI 2024
Help Me Reflect: Leveraging Self-Reflection Interface Nudges to Enhance Deliberativeness on Online Deliberation Platforms
★ Selected
Help Me Reflect: Leveraging Self-Reflection Interface Nudges to Enhance Deliberativeness on Online Deliberation Platforms
★ Selected
PDF
CHI EA 2024
 CHI EA 2024
CHI EA 2024
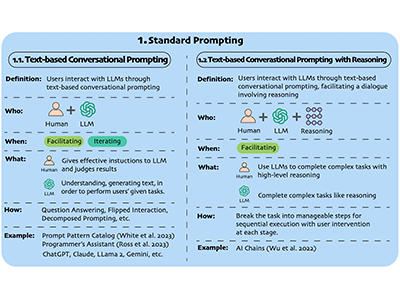
A Taxonomy for Human-LLM Interaction Modes: An Initial Exploration
* equal contribution
★ Selected
A Taxonomy for Human-LLM Interaction Modes: An Initial Exploration
* equal contribution
★ Selected
PDF
Workshop Proposal
 Workshop Proposal
Workshop Proposal
LLMs as Research Tools: Applications and Evaluations in HCI Data Work
LLMs as Research Tools: Applications and Evaluations in HCI Data Work
PDF
UIST 2023
 UIST 2023
UIST 2023
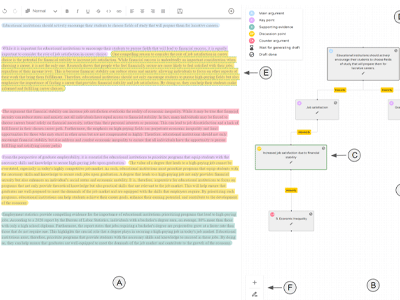
VISAR: A Human-AI Argumentative Writing Assistant with Visual Programming and Rapid Draft Prototyping
★ Selected
VISAR: A Human-AI Argumentative Writing Assistant with Visual Programming and Rapid Draft Prototyping
★ Selected
PDF
TOCHI 2023
 TOCHI 2023
TOCHI 2023
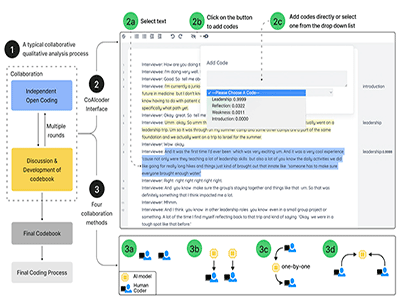
CoAIcoder: Examining the effectiveness of AI-assisted human-to-human collaboration in qualitative analysis
★ Selected
CoAIcoder: Examining the effectiveness of AI-assisted human-to-human collaboration in qualitative analysis
★ Selected
PDF
IMWUT 2023
 IMWUT 2023
IMWUT 2023
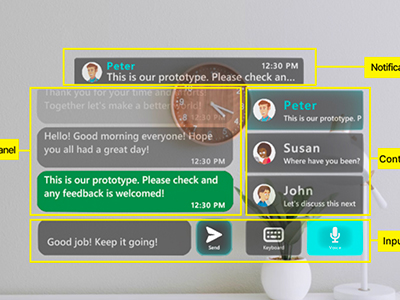
GlassMessaging: Towards Ubiquitous Messaging Using OHMDs
GlassMessaging: Towards Ubiquitous Messaging Using OHMDs
PDF
ICSME 2023
 ICSME 2023
ICSME 2023
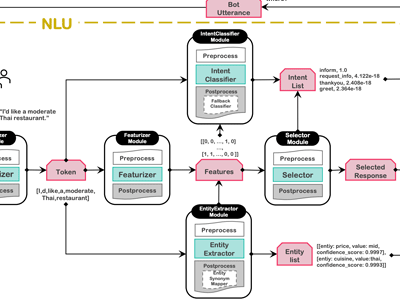
Characterizing the complexity and its impact on testing in ml-enabled systems: A case sutdy on rasa
Characterizing the complexity and its impact on testing in ml-enabled systems: A case sutdy on rasa
PDF
CHI EA 2022
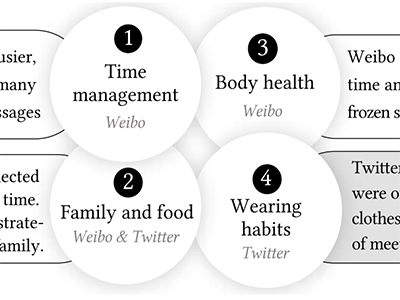 CHI EA 2022
CHI EA 2022
Differences of Challenges of Working from Home (WFH) between Weibo and Twitter Users during COVID-19
Differences of Challenges of Working from Home (WFH) between Weibo and Twitter Users during COVID-19